Obelisk
A smart-searchable notes webapp
Overview
One of my more simplistic projects, Obelisk is a notetaking webapp
that has innate smart-searching capabilities. Although it features import/export features
to easily move data in between instances, it does not link with an externally hosted database
to sync across devices. Everything is in fact stored in local storage, meaning that notes are
device-exclusive. However, this does make data fetching and loading far faster than fetching notes
from an external database, making it a sleek and efficient electron app instance.

Obelisk Home Page
Motivation
The main motivation for this app was to get some basic web development experience.
Obelisk has not only a browser page version, but a web extension and an electron app version, because I wanted
to experience all 3 aspects of web development. I also wanted a way to easily search my notes that wasn't just
pattern matching as well, so this was something that I found useful for personal use as well.
Features
The main features of obelisk include the smart searching capabilities that matches based
on similarity rather than strict pattern matching, as well as the ability to tweak the parameters and weights of this
smart search to better define the search itself. Besides this, Obelisk is nothing more than a simple note taking app
that can live in your browser as a page or extension, or separately as an electron desktop app.
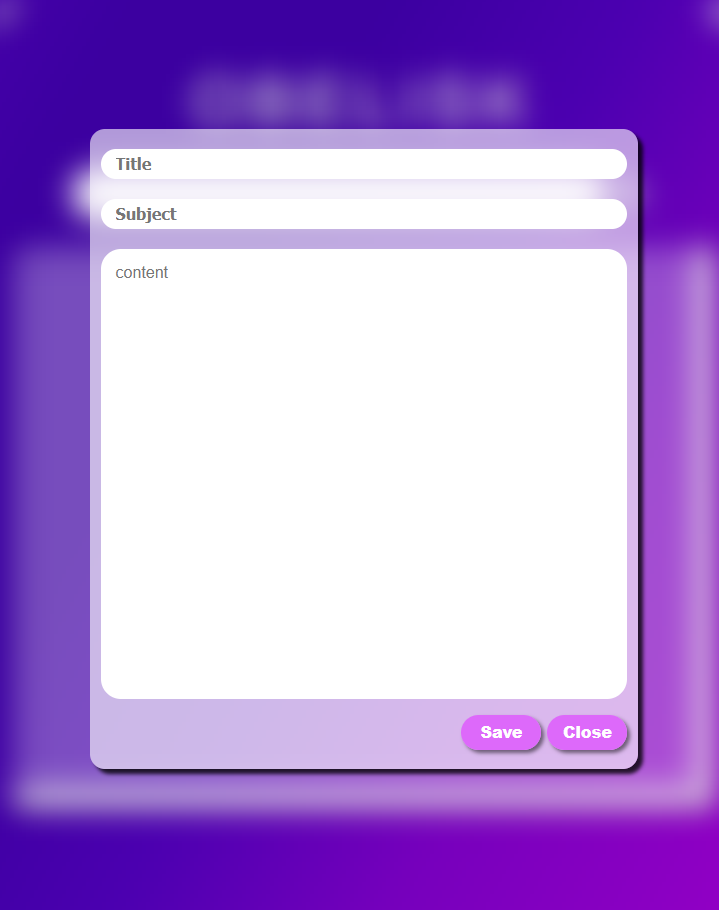
Making a Note in Obelisk
Development Process
Really the biggest aspect of development was implementing the smart similarity search. This wasn't some huge
efficient super search project, so it's definitely not the most efficient. However, it works pretty well for its intensive purposes!
The way this search works is by tokenizing the search phrase, and then searching every note for those tokens with a few rules:
The way this search works is by tokenizing the search phrase, and then searching every note for those tokens with a few rules:
- A value to a found token in a note is weighed in terms of both frequency, as well as importance. If a value is found multiple times, that weight goes up in a linear fashion. If that weight goes up in importance (i.e. if its in the note title, subject, or content), then that weight goes up in an exponential fashion
- Token sequences are also considered too. The more tokens that are found in successive order that matches with the search phrase, the more the weight increases for that search value in an intensely exponential fashion
Technologies
Nothing outside of barebones JavaScript, CSS, and HTML was used for this outside of using firebase as a host. It was
a pretty simple web project relatively, and was pretty fun to do! I typically hate involving heavy web frameworks such as React and other
node packages usually due to how bloated projects can get, so it was really refreshing to work on such a lightweight project.
Takeaways
The biggest takeaway from this mini project for me was the basics of web optimization. To be more specific, using
advanced CSS only when applicable. As I wanted to make Obelisk look very sleek and modern, I added a ton of transitions and complex
compositor effects to give it a more minimal and modern look. However, this makes it run extremely bad on low-spec devices. Even on
phones, the transitions are extremely laggy. In the future, picking and choosing when to use these graphical features is something I need
to be much more mindful of. After all, one of the biggest selling points of a webapp is the ability to run it on any device, anywhere.